Administration and Configuration of XtremeCloud Data Grid-web
Introduction
The XtremeCloud Data Grid-web service provides the cross-cloud or cross-region replication of web cache data for XtremeCloud SSO. We use the Remote Client-Server Mode which provides a managed, distributed, and clusterable data grid service.
Here is a focused view of the cross-cloud traffic from our more complete Enterprise Deployment Diagram.
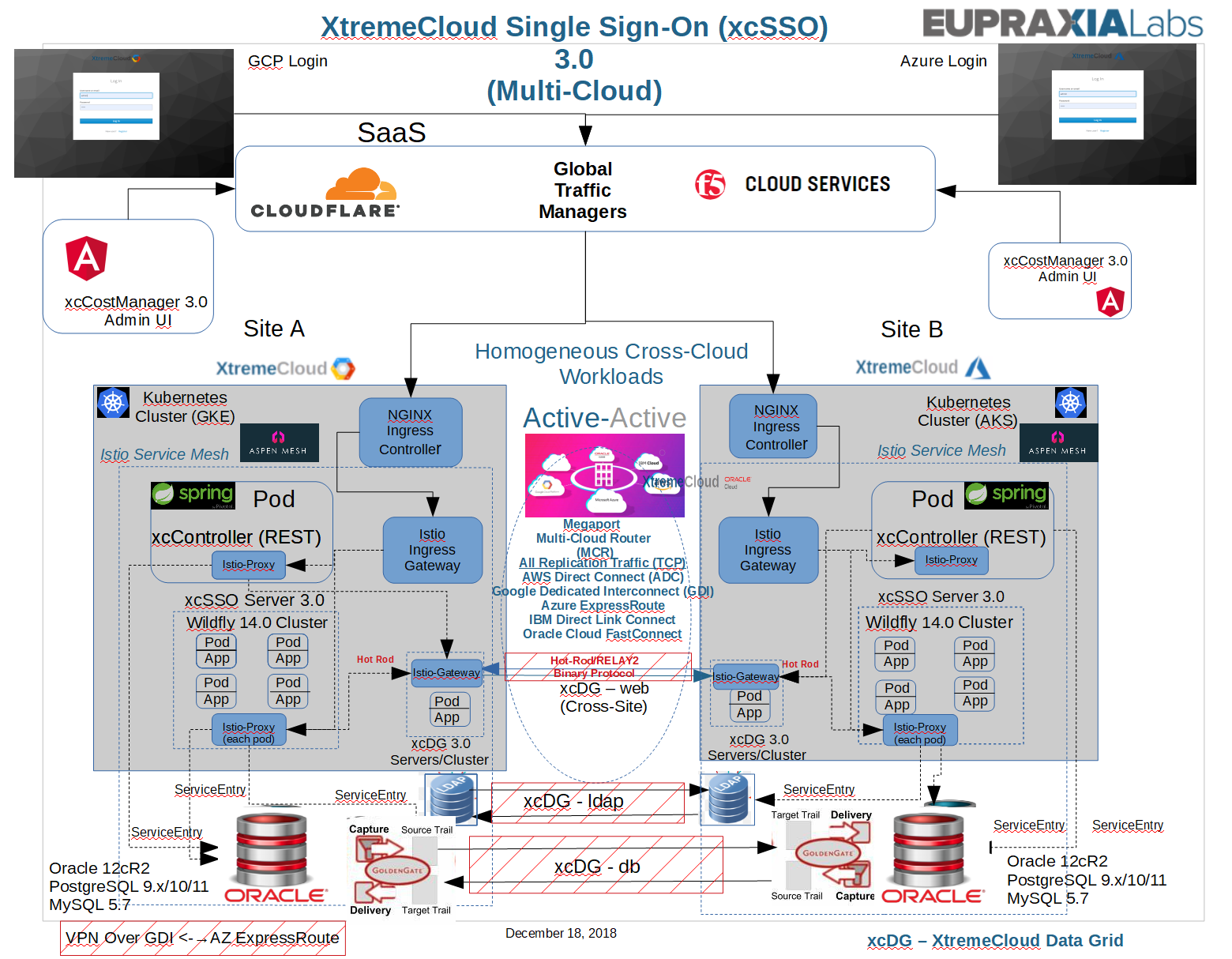{kind=link}
In addition to the cross-cloud replication traffic, the XtremeCloud Data Grid-web service caches persistent data for XtremeCloud SSO to avoid many unnecessary round-trips to its underlying database.
Caching is used for significant performance gains, however this caching presents an additional challenge. When any XtremeCloud SSO Kubernetes pod in a cluster updates any data, all XtremeCloud SSO Kubernetes pods, in both CSPs need to be made aware of it, so that they invalidate particular data from their caches. XtremeCloud SSO uses local XtremeCloud Data Grid-web caches named realms, users, and authorization to cache persistent data to avoid many unnecessary round-trips to the database.
Installation
Prerequisites
As the replication traffic leaves a Cloud Service Provider (CSP) like Google Cloud Platform (GCP/GKE), and transits to another CSP like Microsoft Azure/AKS, it is highly recommended that this traffic be encrypted in-flight. Although the details of a cross-cloud or cross-region Virtual Private Network (VPN) is beyond the scope of this installation documentation, it is recommended.
The XtremeCloud Data Grid-web service is deployed to each Cloud Service Provider (CSP) via CSP-specific Helm Chart. The order in which this is done is important.
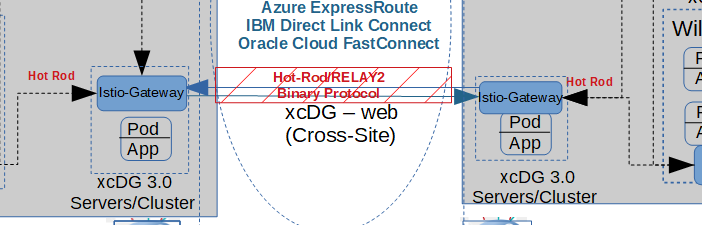
From this excerpt from one of our Helm Charts for XtremeCloud Data Grid-web, it is clear that the remote site’s NGINX load-balancer (ingress) external IP address must be known for the cross-cloud routes to be established.
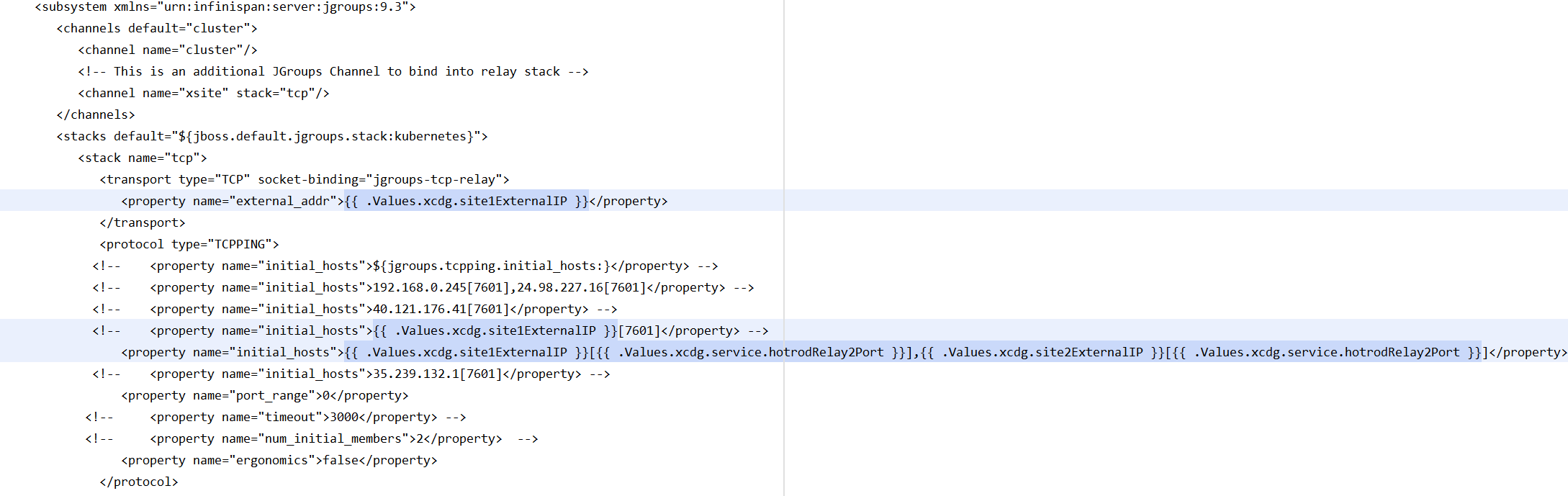
You can see the values in the Kubernetes configMap above are populated from the specific Helm Chart values.yaml file:
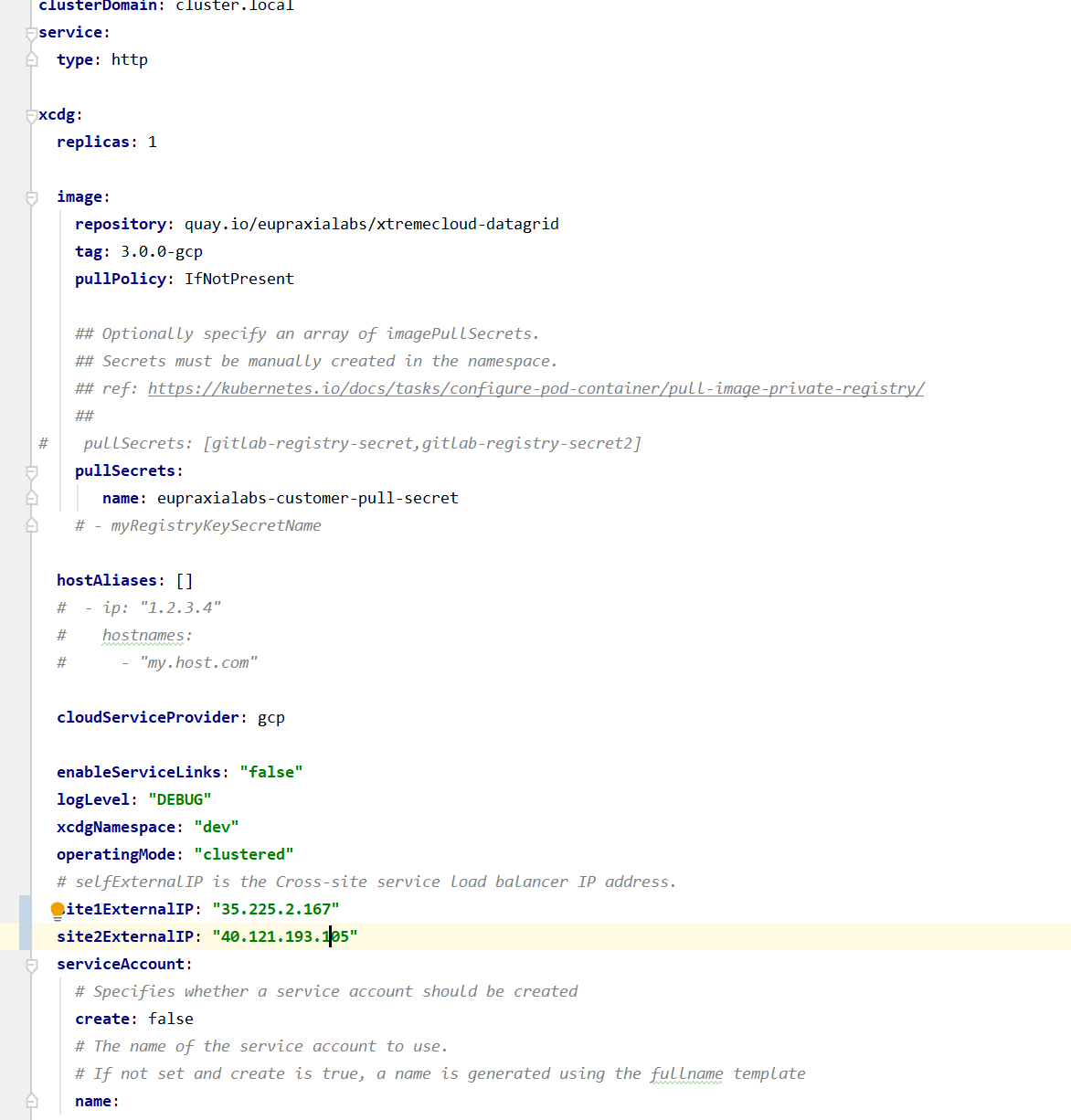
It is through the Helm Chart values.yaml file where desired values are edited. As can be see here, it is very easy to edit the values in the Codefresh user interface.

All Helm Charts provided by Eupraxia Labs are built by CI/CD pipelines, from a source code repository and published to a Helm Chart repository on the site codefresh.io. This is a recommended approach to allow for an easier deployment to multiple Kubernetes clusters such as, Development (Dev), Staging, and Production (PROD).
Codefresh makes it easy to promote from one computing environment to another with its Kanban interface, as shown here:
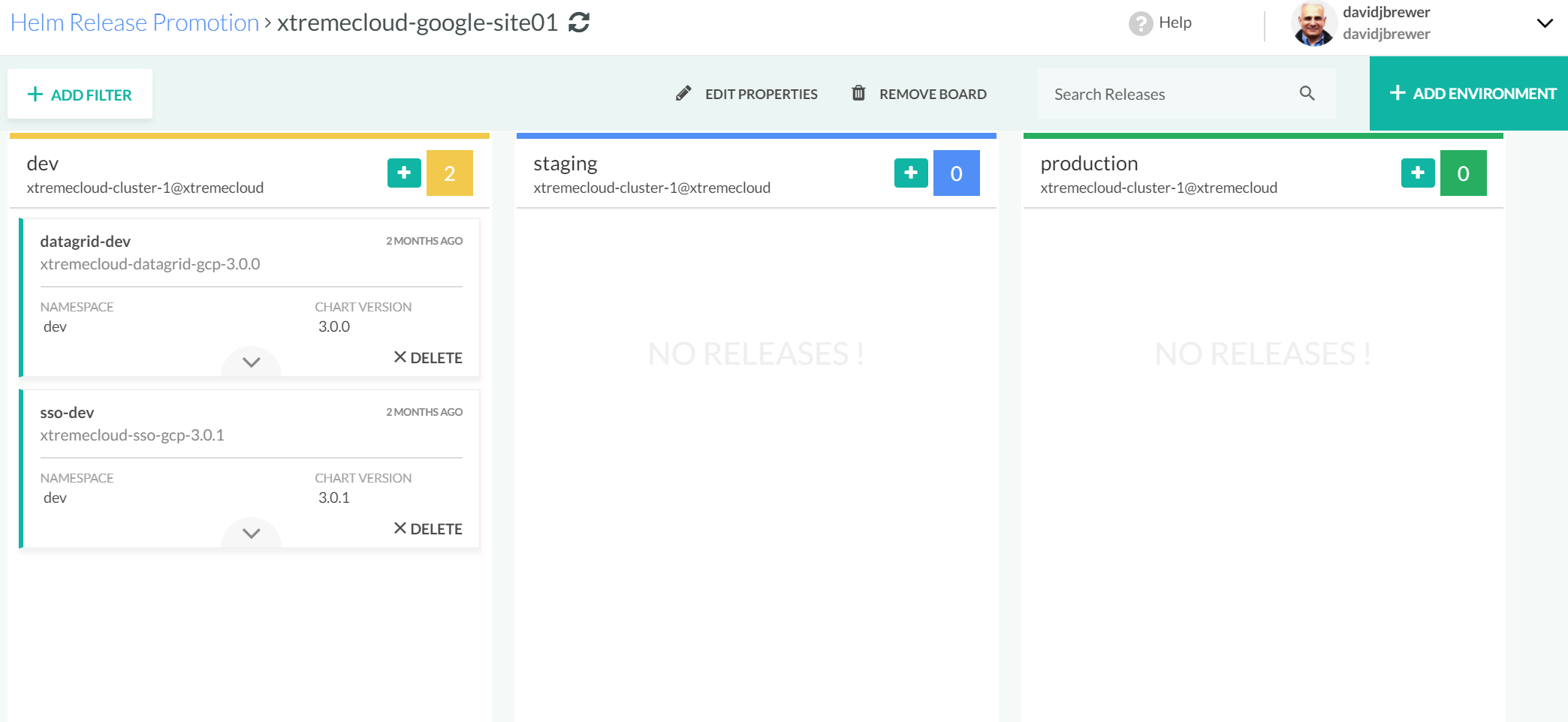
It is not required to use Codefresh as your CI/CD provider, but as we’ve shown it offers some distinct advantages. Refer to Codefresh’s documentation to create an account.
Optionally, if you are subscribed to Eupraxia Labs services, a password-protected Helm Chart repository is available to download all of our charts. The charts can then be stored on your chosen Helm Chart repository or added to your local repository and then deployed from the command line.
Here is a screenshot of some of the Eupraxia Labs-provided Helm Charts:

From Codefresh it is a simple matter to review, edit values as desired, and deploy the Helm Charts to a specific environment (like Dev, Staging, or PROD) from their provided user interface.
However, it is not required to use the Codefresh User Interface. The Helm Charts can be deployed from a command line interface (CLI) .
Perform the Deployment to Both Cloud Service Providers (CSP)
Kubernetes Cluster Prerequisites
Let’s take a look at some of the possible cluster contexts:
[centos@vm-controller ~]$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* az-dev xtremecloud clusterUser_eupraxia-xc_xtremecloud dev
az-staging xtremecloud clusterUser_eupraxia-xc_xtremecloud staging
az-xcsso xtremecloud clusterUser_eupraxia-xc_xtremecloud xcsso
gcp-dev gke_xtremecloud_us-central1-a_xtremecloud-cluster-1 gke_xtremecloud_us-central1-a_xtremecloud-cluster-1 dev
gcp-staging gke_xtremecloud_us-central1-a_xtremecloud-cluster-1 gke_xtremecloud_us-central1-a_xtremecloud-cluster-1 staging
gcp-xcdg gke_xtremecloud_us-central1-a_xtremecloud-cluster-1 gke_xtremecloud_us-central1-a_xtremecloud-cluster-1 xcdg
It is a good practice to have the PROD Kubernetes Cluster separate from Dev and Staging.
Let’s take a look at your local Helm repositories:
[centos@vm-controller ~]$ helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
local http://127.0.0.1:8879/charts
istio.io https://storage.googleapis.com/istio-release/releases/1.1.4/charts/
stakater https://stakater.github.io/stakater-charts
jetstack https://charts.jetstack.io
xtremecloud https://xtremecloud.github.io/xtremecloud-charts
Following a deployment to both Cloud Service Providers (CSP), let’s take a look at the status using the helm command line interface (CLI):
[centos@vm-controller ~]$ helm ls
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
cert-manager 1 Sat Feb 9 15:54:12 2019 DEPLOYED cert-manager-v0.5.2 v0.5.2 kube-system
datagrid-dev 13 Thu Jul 18 13:05:50 2019 DEPLOYED xtremecloud-datagrid-gcp-3.0.0 9.3.1 dev
sso-dev 5 Mon Aug 5 08:39:36 2019 DEPLOYED xtremecloud-sso-gcp-3.0.1 4.8.3 dev
[centos@vm-controller ~]$ kx az-dev
Switched to context "az-dev".
[centos@vm-controller ~]$ helm ls
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
cert-manager 1 Fri Aug 9 12:02:04 2019 DEPLOYED cert-manager-v0.7.1 v0.7.1 cert-manager
datagrid-dev 29 Thu Aug 8 08:01:18 2019 DEPLOYED xtremecloud-datagrid-azure-3.0.0 9.3.3 dev
oldfashioned-badger 1 Sat Jan 19 14:10:59 2019 DEPLOYED nginx-ingress-1.1.4 0.21.0 kube-system
sso-dev 2 Sat Aug 10 12:37:10 2019 DEPLOYED xtremecloud-sso-azure-3.0.2 4.8.3 dev
xtremecloud-nginx 1 Sun Aug 11 08:33:14 2019 DEPLOYED nginx-ingress-1.14.0 0.25.0 kube-system
[centos@vm-controller ~]$
Before any applications, like XtremeCloud Single Sign-On (SSO) can be deployed and started up, make sure the XtremeCloud Data Grid-web route between the CSPs is established as shown:

JConsole is the primary monitoring and management tool for XtremeCloud Data Grid-web. To set it up, refer to this article.
Administration of the XtremeCloud Data Grid-web
When the cross-cloud data grid is up, this will be logged to LogDNA by the XtremeCloud Data Grid-ldap pod that is the site coordinator:
11:44:01,629 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (jgroups-7,_datagrid-dev-xtremecloud-datagrid-gcp-0:site1) ISPN000439: Received new x-site view: [site2]
As you can see, site1 (GCP/GKE by our convention) and site2 (Azure/AKS by our convention) are routing to one another.
As the XtremeCloud Data Grid-web pods start up, you will see the XtremeCloud Data Grid-web podsforming a cluster like this in the logs:
17:07:31,276 INFO [org.infinispan.CLUSTER] (MSC service thread 1-2) ISPN000094: Received new cluster view for channel cluster: [datagrid-dev-xtremecloud-datagrid-gcp-0|1] (2) [datagrid-dev-xtremecloud-datagrid-gcp-0, datagrid-dev-xtremecloud-datagrid-gcp-1]
Operating Considerations and Remediation
Although we do not recommend changing the merge-policy for the XtremeCloud Data Grid-web cache, you have that ability by editing the Kubernetes configMap provided in our Helm Charts.
For reference purposes, we provide the following table. If you need additional information, you may file a Support Ticket or reach out to one of our Solution Architects (SA).

Our default is:
<distributed-cache name="the-default-cache">
<partition-handling when-split="ALLOW_READ_WRITES" merge-policy="PREFERRED_ALWAYS"/>
</distributed-cache>
XtremeCloud Data Grid-web Pods are Unreachable
org.infinispan.client.hotrod.exceptions.transportexception:: Could not fetch transport Caused by: org.infinispan.client.hotrod.exceptions.transportexception:: Could not connect to server: :11222 at org.infinispan.client.hotrod.impl.transport.tcp.tcptransport. <init>(tcptransport.java:82)
This usually means that an XtremeCloud Single Sign-On pod is not able to reach the XtremeCloud Data Grid-web HotRod pod within its own cluster at the Cloud Service Provider. The HotRod pods are behind a Kubernetes Service:
Note: This snippet is from our clustering ConfigMap in the Helm Chart for XtremeCloud SSO
<!-- Site0x (native K8s cluster) follows -->
<outbound-socket-binding name="remote-cache">
<remote-destination host="xcdg-server-hotrod.${env.XTREMECLOUD_DG_NAMESPACE}.svc" port="${remote.cache.port:11222}"/>
</outbound-socket-binding>
If you are using the Alcide Microservices Firewall, in your Kubernetes Cluster, make sure that the policies are configured as expected and the XtremeCloud Data Grid-web pods are reachable.
XtremeCloud SSO Pod Fails to Start Properly
If there are exceptions during a startup of XtremeCloud Single Sign-On pods like this:
16:44:18,321 WARN [org.infinispan.client.hotrod.impl.protocol.codec21] (ServerService Thread Pool -- 57) ISPN004005: Error received from the server: javax.transaction.rollbackexception: ARJUNA016053: Could not commit transaction.
Check the logs of corresponding XtremeCloud Data Grid-web pods of your Site01 (GCP) and check if it has failed to replicate to Site02 (Azure). If Site02 is unavailable, then it is recommended to take it offline, so that XtremeCloud Data Grid-web services won’t attempt to replicate to the offline site.
Note: We have an XtremeCloud numbering convention for the Cloud Service Providers (CSP) that appears throughout our Helm Charts and Ansible Playbooks. That convention also appears in our XtremeCloud Application configurations.
Check the XtremeCloud Data Grid-web statistics, which are available through JMX (command line or JConsole). For example, try to login and then see if the new session was successfully written to both XtremeCloud Data Grid-web servers and is available in the sessions cache there. This can be done indirectly by checking the count of elements in the sessions cache for the MBean
jboss.datagridinfinispan:type=cache,name="clientSessions(repl_sync)",manager="clustered",component=statisticsand attributenumberofentries.
After an XtremeCloud SSO login, there will be one more entry for numberofentries on each XtremeCloud Data Grid-web pod at both sites.
Here’s a look at those entries:
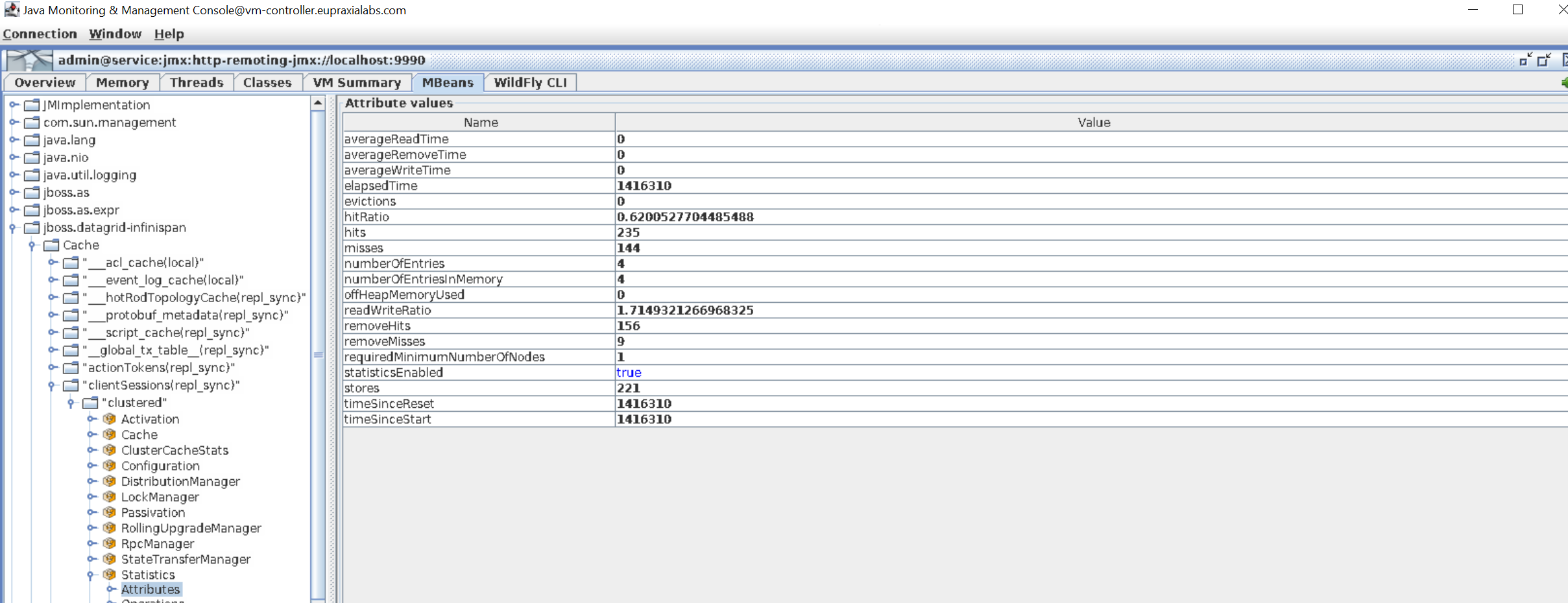
If you are unsure, it is helpful to submit the log files in an Eupraxia Labs Support Ticket on our Customer Portal from all XtremeCloud SSO pods in both clouds. If you updated the entity, such as user, on an XtremeCloud Single Sign-On user interface (UI) on Site1 and you do not see that entity updated on the XtremeCloud Single Sign-On user interface (UI) on Site2, then the issue can be either in the replication of the bi-directional replication in the database itself or that XtremeCloud Single Sign-On caches are not properly invalidated.
Manually connect to the database and check if data is updated as expected. This is specific to every database, so you will need to consult the documentation for your implemented database.
Troubleshooting
Let’s take a look at this error and how to recover from it: ISPN000136:
Oct 11 09:29:35 datagrid-dev-xtremecloud-datagrid-azure-1 xtremecloud-datagrid-azure 14:29:35,897 ERROR [org.infinispan.interceptors.impl.InvocationContextInterceptor] (jgroups-4452,datagrid-dev-xtremecloud-datagrid-azure-1) ISPN000136: Error executing command RemoveExpiredCommand, writing keys [WrappedByteArray{bytes=[B0x033E243835316333..[39], hashCode=496789814}]: org.infinispan.remoting.RemoteException: ISPN000217: Received exception from datagrid-dev-xtremecloud-datagrid-azure-0, see cause for remote stack trace 10.244.5.6
content pending
Let’s take a look at this:
ERROR [org.infinispan.interceptors.impl.InvocationContextInterceptor] (pool-9-thread-1) ISPN000136: Error executing command RemoveExpiredCommand, writing keys [WrappedByteArray{bytes=[B0x033E243331366434..[39], hashCode=3940354}]: org.infinispan.util.concurrent.TimeoutException: ISPN000299: Unable to acquire lock after 0 milliseconds for key WrappedByteArray{bytes=[B0x033E243331366434..[39], hashCode=3940354} and requestor GlobalTx:datagrid-dev-xtremecloud-datagrid-gcp-1:3724. Lock is held by GlobalTx:datagrid-dev-xtremecloud-datagrid-gcp-0:157083
content pending
Here are some miscellaneous Kubernetes command to help with administration.
If you want to do a quick scale up of your XtremeCloud Data Grid-web cluster:
kubectl scale --replicas=2 sts/$(kubectl get sts --namespace=dev | grep datagrid | awk '{print $1}') --namespace=dev
As a result, your Statefulset deployment is edited (excerpt follows):
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: apps/v1
kind: StatefulSet
metadata:
creationTimestamp: "2019-07-17T20:16:02Z"
generation: 29
labels:
app: xtremecloud-datagrid-gcp
chart: xtremecloud-datagrid-gcp-3.0.0
heritage: Tiller
release: datagrid-dev
name: datagrid-dev-xtremecloud-datagrid-gcp
namespace: dev
resourceVersion: "70726609"
selfLink: /apis/apps/v1/namespaces/dev/statefulsets/datagrid-dev-xtremecloud-datagrid-gcp
uid: b30ee425-a8cf-11e9-83e8-42010a80021c
spec:
podManagementPolicy: Parallel
replicas: 2
Now, two (2) XtremeCloud Data Grid-web pods are running to support the distributed replication for XtremeCloud SSO:
[centos@vm-controller ~]$ k get po
NAME READY STATUS RESTARTS AGE
datagrid-dev-xtremecloud-datagrid-gcp-0 1/1 Running 0 19d
datagrid-dev-xtremecloud-datagrid-gcp-1 1/1 Running 0 4m40s
logdna-agent-7qcqr 1/1 Running 0 5d22h
logdna-agent-bk7qn 1/1 Running 0 44d
logdna-agent-cwckn 1/1 Running 0 44d
logdna-agent-wwcgt 1/1 Running 0 44d
sso-dev-xtremecloud-sso-gcp-0 1/1 Running 0 16h