XtremeCloud Single Sign-On (SSO)
Concept of Operations
![]()
This is Single Sign-On at the Xtreme level. This documentation section serves as the Concept of Operations Guide. Links will be provided throughout our documentation to Installation Guides, Administration Guides, User Guides, and Development Guides.
The following diagram may appear a little daunting, however it is going to be explained in detail.
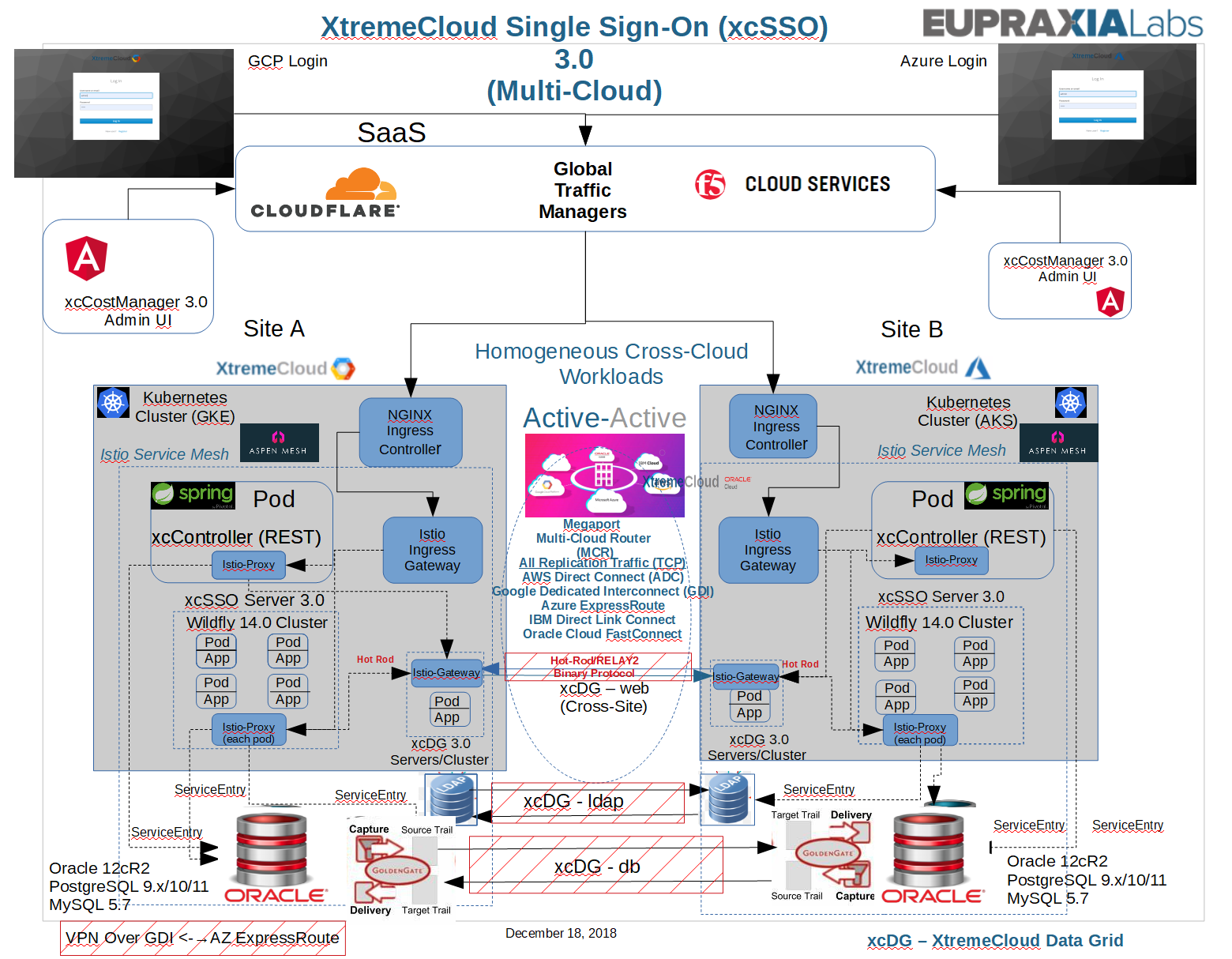
Introduction
XtremeCloud Single Sign-On (SSO) is a multi-cloud application as we define it.
First, let’s discuss some of the functionality of the XtremeCloud Single Sign-On (SSO) multi-cloud solution.
XtremeCloud SSO, with Keycloak as a underlying open source component, supports both OpenID Connect (an extension to OAuth 2.0) and SAML 2.0. When securing clients and services the first thing you need to decide is which of the two you are going to use. If you want you can also choose to secure some with OpenID Connect and others with SAML.
To secure clients and services you are also going to need an adapter or library for the protocol you’ve selected. XtremeCloud SSO comes with its own adapters for selected platforms, but it is also possible to use generic OpenID Connect Resource Provider and SAML Service Provider libraries.
Features
-
Single-Sign On and Single-Sign Out for browser applications.
-
OpenID Connect (OIDC) support.
-
OAuth 2.0 support.
-
SAML support.
-
Identity Brokering - Authenticate with external OpenID Connect or SAML Identity Providers.
-
Social Login - Enable login with Google, GitHub, Facebook, Twitter, and other social networks.
-
User Federation - Sync users from XtremeCloud Data Grid-ldap , other LDAP servers, and Microsoft Active Directory (AD) servers.
-
Kerberos bridge - Automatically authenticate users that are logged-in to a Kerberos server.
-
Admin Console for central management of users, roles, role mappings, clients and configuration.
-
Account Management console that allows users to centrally manage their account.
-
Theme support - Customize all user facing pages to integrate with your applications and branding.
-
Two-factor Authentication - Support for TOTP/HOTP via Google Authenticator or FreeOTP.
-
Login flows - optional user self-registration, recover password, verify email, require password update, etc.
-
Session management - Admins and users themselves can view and manage user sessions.
-
Token mappers - Map user attributes, roles, etc. how you want into tokens and statements.
-
Not-before revocation policies per realm, application and user.
-
CORS support - Client adapters have built-in support for CORS.
-
Service Provider Interfaces (SPI) - A number of SPIs to enable customizing various aspects of the server. Authentication flows, user federation providers, protocol mappers and many more.
-
Client adapters for JavaScript applications, WildFly, JBoss EAP, Fuse, Tomcat, Jetty, Spring, etc.
-
Supports any platform/language that has an OpenID Connect Resource Provider library or SAML 2.0 Service Provider library
Details on how to administer this cloud-native application is covered in the Administration and Configuration Guide.
Global Traffic Management
In order to support a multi-cloud active-active deployment, there must be a global load balancer to route a browser-based http service request to one cloud or the other in a two-way Cloud Service Provider (CSP) mesh. In the diagram above, the two (2) CSPs are Google Cloud and Microsoft Azure.
Eupraxia Labs supports two (2) Global Services Load Balancer (GSLB) SaaS solutions: 1) Cloudflare, and 2) F5 Cloud Services. The versions supported are show in the Certifications Matrix.
XtremeCloud applications users enter a URL to a globally load-balanced service and is routed to a CSP based on several factors. If the user is already authenticated, the request will go to the same CSP that initially authenticated the request. This session persistence, or session stickiness, is provided by the Global Services Load Balancer using session cookies.
In the Load Balancing in the Wildfly Cluster section below, we will detail the load-balancing and session persistence of our cloud-native application containers in the application server (Wildfly) clusters.
Cloud Services Provider (CSP) Kubernetes Clusters
We will provide specific prerequisites for creation of the Kubernetes Cluster at each CSP. Depending on the choice of CSP in a two-way CSP mesh, the prerequistes are created in a specific manner, although there are many similarities amongst the CSPs.
For reference purposes, the table below is provided to make it clearer as to what site is being referred to in our documentation and CSP configurations.
| Site Number | Site Name | Cluster Service Name |
|---|---|---|
| 01 | Google Cloud Platform (GCP) | Google Kubernetes Engine (GKE) |
| 02 | Microsoft Azure | Azure Kubernetes Service (AKS) |
| 03 | Oracle Cloud | Oracle Kubernetes Engine (OKE) |
| 04 | IBM Cloud | IBM Kubernetes Engine (IKE) |
| 05 | Amazon Web Services (AWS) | Elastic Kubernetes Engine (EKS) |
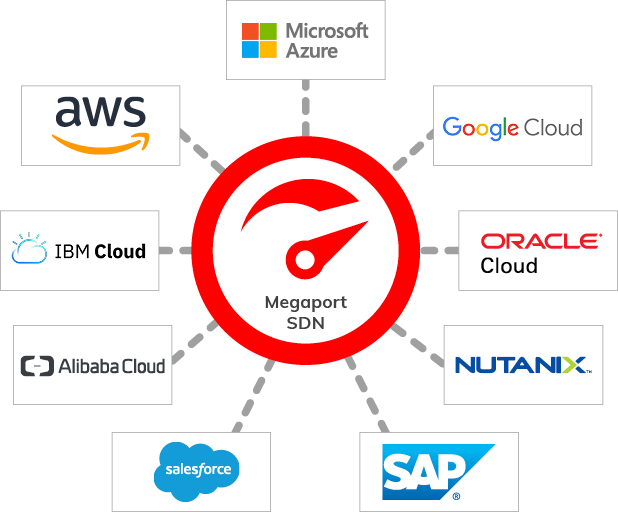
Multi-Cloud High Speed Interconnects
Cloud Services Provider’s (CSP) alliances, like that of Oracle’s and Microsoft’s, will provide the kind of high speed interconnects to replicate traffic between each other. However, those interconnects may be limited to provide the types of services that these two (2) CSPs have envisioned and it is not necessary to wait for these alliances to occur.
Additionally, it is important that replication traffic be connected via high-speed interconnects irrespective of CSP partnerships. For that reason, we recommend the use of Megaport for the XtremeCloud Data Grid that supports XtremeCloud applications. A strong commitment by Megaport, is essential, to preserve the network connectivity and avoid any partitioning of the network, i.e., the Partition Tolerance addressed in our multi-cloud CAP discussion. However, it is not a perfect world. It’s inevitable. As you will see later, we will address how to manage and eventually recover from a split-brain scenario at any of the three (3) tiers of our XtremeCloud Data Grid.
NGINX Kubernetes Ingress Controller (KIC)
By default, XtremeCloud applications running in pods are not accessible from the external network, but only by other pods within the Kubernetes cluster. Kubernetes has a built‑in configuration for TCP/UDP and HTTP load balancing, called Ingress, that defines rules for external connectivity to the pods represented by one or more Kubernetes services. Users who need to provide external access to their Kubernetes services create an Ingress resource that defines rules, including the URI path, backing service name, and other information. An Ingress controller then automatically configures a frontend load balancer to implement the Ingress rules. Not unexpectedly, the NGINX Ingress Controller configures NGINX to load balance Kubernetes services.
The NGINX Kubernetes Ingress Controller (KIC) for XtremeCloud SSO is configured via a provided Helm Chart that allows for a highly configurable solution.
Our standard Development (Dev), Staging, and Production (PROD) Kubernetes clusters are ready to provide ingress access to the customer-provided URL for providing identity and access management (IAM) services. If SSL/TLS termination is desired at the edge, and an Istio Microservices Service Mesh is not desired, this would be your preferred solution. To ease the burden of managing digital certificates in the Dev and Staging clusters, we recommend the use of our Let’s Encrypt solution for those clusters. Optionally, depending on your security requirements, you may choose to use the Let’s Encrypt service in a production environment as well.
If pass-through encryption to the cloud-native container is desired (end-to-end encryption), NGINX can still provide a valuable service. If there is a situation where NGINX needs to be in the mix, like load balancing to a non-Kubernetes service, the desire to terminate SSL/TLS at NGINX might be appropriate. Therefore, NGINX could be used for non-mesh components outside of Istio/Aspen Mesh, particularly if there is no interest in integrating with the service mesh. Additionally, Aspen Mesh can be configured to extend the mesh to outside components via ServiceEntry. This is exactly how XtremeCloud SSO communicates from the service mesh to its underlying database hosted on a virtual machine (VM) or raw iron. This ServiceEntry provides mutual TLS (mTLS) between containers in the mesh and services external to the service mesh.
Aspen Mesh (Istio) Envoy Ingress Controller
Istio makes it easy to create a network of deployed services with load balancing, service-to-service authentication, monitoring, and more, with few or no code changes in service code. You add Istio support to services by deploying a special sidecar proxy throughout your environment that intercepts all network communication between microservices, then configure and manage Istio using its control plane functionality, which includes:
-
Automatic load balancing for HTTP, gRPC, WebSocket, and TCP traffic.
-
Fine-grained control of traffic behavior with rich routing rules, retries, failovers, and fault injection.
-
A pluggable policy layer and configuration API supporting access controls, rate limits and quotas.
-
Automatic metrics, logs, and traces for all traffic within a cluster, including cluster ingress and egress.
-
Secure service-to-service communication in a cluster with strong identity-based authentication and authorization.
-
Istio is designed for extensibility and meets diverse deployment needs.
As mentioned in Item 5 above, Aspen Mesh provides the transport layer security (TLS), within the Kubernetes cluster. In this case, the encrypted payload from the user’s browser, is passed through the edge and all the way to the cloud-native application containers. The injected Istio sidecar will pass the decrypted payload to the container via a local loopback interface within the pod. As part of an Acceptance Test, for completion of our XtremeCloud Quick Start packages for subscribed customers, we demonstrate this end-to-end encryption by sniffing the traffic in the clusters. Only then, are you absolutely sure that your data is secure. We use the kubectl sniff plug-in to prove this out.
Earlier, the ServiceEntry capability was lightly touched upon. ServiceEntry enables adding additional entries into Istio’s internal service registry, so that auto-discovered services in the mesh can access/route to these manually specified services. A service entry describes the properties of a service (DNS name, VIPs, ports, protocols, endpoints). These services could be external to the mesh (e.g., web APIs) or mesh-internal services that are not part of the platform’s service registry (e.g., a set of VMs talking to services in Kubernetes). More specifically, like the XtremeCloud Single Sign-On (SSO) configuration, let’s look at the associated ServiceEntry for routing to an Oracle RAC cluster. This configuration is part of the provided Aspen Mesh artifacts in an Eupraxia Labs-configured cluster.
---
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: oracle-cluster01
spec:
hosts:
- xtremecloud-gke-scan.eupraxia.io
location: MESH_EXTERNAL
ports:
- name: xtremecloud-oracle
number: 1521
protocol: tcp
resolution: DNS
The fully qualified domain name (FQDN) of xtremecloud-gke-scan.eupraxia.io is resolving to three (3) IP addresses since the cluster is a three-node Oracle RAC cluster.
Single Client Access Name (SCAN) is a feature used in Oracle Real Application Clusters (RAC) environments that provides a single name for clients to access any Oracle Database running in a cluster. You can think of SCAN as a cluster alias for databases in the cluster. The benefit is that the client’s connect information does not need to change if you add or remove nodes or databases in the cluster.
xtremecloud-gke-scan.eupraxia.io IN A 133.22.67.194
IN A 133.22.67.193
IN A 133.22.67.192
Load Balancing of the Wildfly-based XtremeCloud SSO Container Cluster
The XtremeCloud Single Sign-On (SSO) cloud-native containers are clustered, with Wildfly-specific configurations, and load-balanced by Kubernetes services. Our default load balancing algorithm is ip-hash. We tie the client request to a particular XtremeCloud SSO pod — in other words, we make the client’s session sticky or persistent in terms of always trying to select a particular Kubernetes pod — the ip-hash load balancing method is how we do this with our NGINX Kubernetes Ingress Controller. With ip-hash, the client’s IP address is used as a hashing key to determine which pod in our Wildfly cluster will be selected for the client’s requests. This method ensures that the requests from the same client will always be directed to the same Kubernetes XtremeCloud SSO pod except when this pod is unavailable.
Let’s take a look at the configuration with ip-hash set as the load balancing algorith between the NGINX KIC and the XtremeCloud SSO cluster of pods. Note the annotation of *kubernetes.io/load-balance: ip_hash.
[centos@vm-controller ~]$ kubectl get ing xtremecloud-sso-gcp -o yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
certmanager.k8s.io/acme-http01-edit-in-place: "true"
certmanager.k8s.io/cluster-issuer: letsencrypt-staging
ingress.kubernetes.io/backends: '{"k8s-be-31675--6a6428c48139a940":"HEALTHY"}'
ingress.kubernetes.io/forwarding-rule: k8s-fw-dev-xtremecloud-sso-gcp--6a6428c48139a940
ingress.kubernetes.io/https-forwarding-rule: k8s-fws-dev-xtremecloud-sso-gcp--6a6428c48139a940
ingress.kubernetes.io/https-target-proxy: k8s-tps-dev-xtremecloud-sso-gcp--6a6428c48139a940
ingress.kubernetes.io/ssl-cert: k8s-ssl-957efa8d09616392-914bb77d78fb02e2--6a6428c48139a940
ingress.kubernetes.io/target-proxy: k8s-tp-dev-xtremecloud-sso-gcp--6a6428c48139a940
ingress.kubernetes.io/url-map: k8s-um-dev-xtremecloud-sso-gcp--6a6428c48139a940
kubernetes.io/ingress.global-static-ip-name: xcsso-dev-ip
kubernetes.io/load-balance: ip_hash
creationTimestamp: "2019-07-23T15:59:39Z"
generation: 5
labels:
app: xtremecloud-sso-gcp
name: xtremecloud-sso-gcp
namespace: dev
resourceVersion: "67822366"
selfLink: /apis/extensions/v1beta1/namespaces/dev/ingresses/xtremecloud-sso-gcp
uid: e094aee2-ad62-11e9-83e8-42010a80021c
spec:
backend:
serviceName: sso-dev-xtremecloud-sso-gcp
servicePort: 8080
tls:
- hosts:
- sso-gke-dev.eupraxialabs.com
secretName: xcsso-dev-server-tls
status:
loadBalancer:
ingress:
- ip: 35.201.112.128
Now let’s address how the clustered containers of XtremeCloud SSO are accessed from outside of the Kubernetes Cluster.
Kubernetes is an open source container scheduling and orchestration system originally created by Google and then donated to the Cloud Native Computing Foundation (CNCF). Kubernetes automatically schedules containers to run evenly among a cluster of servers, abstracting this complex task from developers and operators. Clearly, Kubernetes has emerged as the favored container orchestrator and scheduler. The NGINX Ingress Controller for Kubernetes (KIC) provides enterprise‑grade delivery services for Kubernetes applications, with benefits for users of both open source NGINX. With the NGINX Ingress Controller for Kubernetes, you get basic load balancing, SSL/TLS termination, support for URI rewrites, and upstream SSL/TLS encryption.
As seen in the creation of the KIC for our XtremeCloud SSO containers, we have specified kubernetes.io/ingress.class: nginx to ensure we get the NGINX Ingress Controller.
An additional feature in this deployment is the use of the Let’s Encrypt service for automatically issuing certificates to our NGINX Ingress Controller. For details on our implementation, please refer to our documentation.
kind: Ingress
metadata:
annotations:
certmanager.k8s.io/cluster-issuer: letsencrypt-staging
ingress.kubernetes.io/ssl-passthrough: "true"
kubernetes.io/ingress.class: nginx
# the ip_hash load balancing algorithm provides stickiness to the same xtremecloud SSO pod
kubernetes.io/load-balance: ip_hash
kubernetes.io/tls-acme: “true”
nginx.ingress.kubernetes.io/affinity: cookie
nginx.ingress.kubernetes.io/session-cookie-expires: "172800"
nginx.ingress.kubernetes.io/session-cookie-max-age: "172800"
nginx.ingress.kubernetes.io/session-cookie-name: nginx-route
name: xtremecloud-sso-azure
spec:
rules:
- host: sso.eupraxialabs.com
http:
paths:
- backend:
serviceName: sso-dev-xtremecloud-sso-azure
servicePort: 8080
path: /
tls:
- hosts:
- sso.eupraxialabs.com
secretName: sso-eupraxialabs-com
Scaling of the XtremeCloud SSO Wildfly-based Docker Container-based Cluster
The XtremeCloud Single Sign-On (SSO) cloud-native containers are deployed to scale automatically.
We’re going to address autoscaling in each Cloud Services Provider (CSP) at two levels:
-
Autoscaling at Pod Level: This plane includes the Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA), both of which scale your containers based on available resources.
-
Autoscaling at Cluster Level: The Cluster Autoscaler (CA) manages this plane of scalability by scaling the number of worker nodes inside your Cluster up or down as necessary.
Horizontal Pod Autoscaler (HPA) scales the number of Pod replicas for you in our Cluster. The move is triggered by CPU or memory to scale up or down as necessary. However, it’s possible to configure HPA to scale Pods according to varied, external, and custom metrics (metrics.k8s.io, external.metrics.k8s.io, and custom.metrics.k8s.io).
Vertical Pod Autoscaler (VPA) Built predominantly for stateful services, VPA adds CPU or memory to Pods as required—it also works for both stateful and stateless Pods, as well. To make these changes, VPA restarts Pods to update new CPU and memory resources, which can be configured to set off in reaction to Out of Memory (out of memory) events. Upon restarting Pods, VPA always ensures there is the minimum number according to the Pods Distribution Budget (PDB) which you can set along with a resource allocation maximum and minimum rate.
Cluster Autoscaler (CA) The second layer of autoscaling involves CA, which automatically adjusts the size of the cluster if:
-
Any of our pod/s fail to run and fall into a pending state due to insufficient capacity in the Cluster, in which case a scale-up event will occur.
-
Nodes in the cluster have been underutilized for a certain period of time and there is a chance to relocate their pods on reaming nodes, in which case a scale-down event will occur.
CA makes routine checks to determine whether any pods are in a pending state waiting for extra resources or if Cluster nodes are being underutilized. The function then adjusts the number of Cluster nodes accordingly if more resources are required. CA interacts with the Cloud Services Provider (CSP) to request additional nodes or shut down idle ones and ensures the scaled-up Cluster remains within the limitations set by you.
Let’s take a look at the result of some load testing that caused autoscaling at the Pod Level. It can be seen below that HPA did take effect and two (2) additional XtremeCloud SSO pods were started.
[centos@vm-controller ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
datagrid-dev-xtremecloud-datagrid-gcp-0 1/1 Running 0 13d
logdna-agent-7qcqr 1/1 Running 0 3m32s
logdna-agent-bk7qn 1/1 Running 0 39d
logdna-agent-cwckn 1/1 Running 0 39d
logdna-agent-wwcgt 1/1 Running 0 39d
sso-dev-xtremecloud-sso-gcp-0 1/1 Running 0 13d
sso-dev-xtremecloud-sso-gcp-1 1/1 Running 0 8m28s
sso-dev-xtremecloud-sso-gcp-2 0/1 Running 0 2m28s
[centos@vm-controller ~]$ kubectl get events
LAST SEEN TYPE REASON KIND MESSAGE
3m24s Warning FailedScheduling Pod 0/4 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 3 node(s) didn't match node selector.
3m28s Normal NotTriggerScaleUp Pod pod didn't trigger scale-up (it wouldn't fit if a new node is added): 1 node(s) didn't match node selector
3m24s Normal Scheduled Pod Successfully assigned dev/logdna-agent-7qcqr to gke-xtremecloud-cluster--default-pool-d03f8f59-sht0
3m7s Normal Pulling Pod pulling image "logdna/logdna-agent:latest"
2m27s Normal Pulled Pod Successfully pulled image "logdna/logdna-agent:latest"
2m25s Normal Created Pod Created container
2m25s Normal Started Pod Started container
3m42s Normal SuccessfulCreate DaemonSet Created pod: logdna-agent-7qcqr
8m38s Normal Scheduled Pod Successfully assigned dev/sso-dev-xtremecloud-sso-gcp-1 to gke-xtremecloud-cluster--default-pool-d03f8f59-w8d2
8m36s Normal Pulling Pod pulling image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
8m35s Normal Pulled Pod Successfully pulled image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
8m34s Normal Created Pod Created container
8m34s Normal Started Pod Started container
5m32s Warning Unhealthy Pod Readiness probe failed: Get http://10.52.1.225:8080/auth/realms/master: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
4m37s Warning FailedScheduling Pod 0/3 nodes are available: 1 Insufficient cpu, 2 Insufficient memory.
4m30s Normal TriggeredScaleUp Pod pod triggered scale-up: [{https://content.googleapis.com/compute/v1/projects/xtremecloud/zones/us-central1-a/instanceGroups/gke-xtremecloud-cluster--default-pool-d03f8f59-grp 3->4 (max: 5)}]
3m42s Normal Scheduled Pod Successfully assigned dev/sso-dev-xtremecloud-sso-gcp-2 to gke-xtremecloud-cluster--default-pool-d03f8f59-sht0
3m42s Warning NetworkNotReady Pod network is not ready: [runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: Kubenet does not have netConfig. This is most likely due to lack of PodCIDR]
3m27s Normal Pulling Pod pulling image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
2m33s Normal Pulled Pod Successfully pulled image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
2m29s Normal Created Pod Created container
2m29s Normal Started Pod Started container
6s Warning Unhealthy Pod Readiness probe failed: Get http://10.52.3.2:8080/auth/realms/master: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
8m38s Normal SuccessfulCreate StatefulSet create Pod sso-dev-xtremecloud-sso-gcp-1 in StatefulSet sso-dev-xtremecloud-sso-gcp successful
8m38s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target
4m38s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 3; reason: cpu resource utilization (percentage of request) above target
4m38s Normal SuccessfulCreate StatefulSet create Pod sso-dev-xtremecloud-sso-gcp-2 in StatefulSet sso-dev-xtremecloud-sso-gcp successful
2m2s Normal UpdatedLoadBalancer Service Updated load balancer with new hosts
[centos@vm-controller ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
datagrid-dev-xtremecloud-datagrid-gcp-0 1/1 Running 0 13d
logdna-agent-7qcqr 1/1 Running 0 4m
logdna-agent-bk7qn 1/1 Running 0 39d
logdna-agent-cwckn 1/1 Running 0 39d
logdna-agent-wwcgt 1/1 Running 0 39d
sso-dev-xtremecloud-sso-gcp-0 1/1 Running 0 13d
sso-dev-xtremecloud-sso-gcp-1 1/1 Running 0 8m56s
sso-dev-xtremecloud-sso-gcp-2 1/1 Running 0 4m56s
After a couple of minutes, the load is below our 50% CPU target.
[centos@vm-controller ~]$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
sso-dev-xtremecloud-sso-gcp StatefulSet/sso-dev-xtremecloud-sso-gcp 27%/50% 1 3 3 18h
Let’s look at details of this specific HorizonatalPodAutoscaler:
[centos@vm-controller ~]$ kubectl get hpa -o yaml
apiVersion: v1
items:
- apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:
autoscaling.alpha.kubernetes.io/conditions: '[{"type":"AbleToScale","status":"True","lastTransitionTime":"2019-10-08T21:02:30Z","reason":"ReadyForNewScale","message":"recommended
size matches current size"},{"type":"ScalingActive","status":"True","lastTransitionTime":"2019-10-08T21:02:30Z","reason":"ValidMetricFound","message":"the
HPA was able to successfully calculate a replica count from cpu resource utilization
(percentage of request)"},{"type":"ScalingLimited","status":"False","lastTransitionTime":"2019-10-09T15:24:47Z","reason":"DesiredWithinRange","message":"the
desired count is within the acceptable range"}]'
autoscaling.alpha.kubernetes.io/current-metrics: '[{"type":"Resource","resource":{"name":"cpu","currentAverageUtilization":35,"currentAverageValue":"71m"}}]'
creationTimestamp: "2019-10-08T21:02:15Z"
name: sso-dev-xtremecloud-sso-gcp
namespace: dev
resourceVersion: "68459802"
selfLink: /apis/autoscaling/v1/namespaces/dev/horizontalpodautoscalers/sso-dev-xtremecloud-sso-gcp
uid: e7e2c5ba-ea0e-11e9-83e8-42010a80021c
spec:
maxReplicas: 3
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: sso-dev-xtremecloud-sso-gcp
targetCPUUtilizationPercentage: 50
status:
currentCPUUtilizationPercentage: 35
currentReplicas: 3
desiredReplicas: 3
lastScaleTime: "2019-10-09T15:13:24Z"
kind: List
metadata:
resourceVersion: ""
selfLink: ""
After a few minutes of a reduced workload, idle pods are beginning to get deleted as seen by the New size: 2 event in the KIND column:
[centos@vm-controller ~]$ k get events
LAST SEEN TYPE REASON KIND MESSAGE
20m Warning FailedScheduling Pod 0/4 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 3 node(s) didn't match node selector.
20m Normal NotTriggerScaleUp Pod pod didn't trigger scale-up (it wouldn't fit if a new node is added): 1 node(s) didn't match node selector
20m Normal Scheduled Pod Successfully assigned dev/logdna-agent-7qcqr to gke-xtremecloud-cluster--default-pool-d03f8f59-sht0
20m Normal Pulling Pod pulling image "logdna/logdna-agent:latest"
19m Normal Pulled Pod Successfully pulled image "logdna/logdna-agent:latest"
19m Normal Created Pod Created container
19m Normal Started Pod Started container
20m Normal SuccessfulCreate DaemonSet Created pod: logdna-agent-7qcqr
25m Normal Scheduled Pod Successfully assigned dev/sso-dev-xtremecloud-sso-gcp-1 to gke-xtremecloud-cluster--default-pool-d03f8f59-w8d2
25m Normal Pulling Pod pulling image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
25m Normal Pulled Pod Successfully pulled image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
25m Normal Created Pod Created container
25m Normal Started Pod Started container
22m Warning Unhealthy Pod Readiness probe failed: Get http://10.52.1.225:8080/auth/realms/master: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
21m Warning FailedScheduling Pod 0/3 nodes are available: 1 Insufficient cpu, 2 Insufficient memory.
21m Normal TriggeredScaleUp Pod pod triggered scale-up: [{https://content.googleapis.com/compute/v1/projects/xtremecloud/zones/us-central1-a/instanceGroups/gke-xtremecloud-cluster--default-pool-d03f8f59-grp 3->4 (max: 5)}]
20m Normal Scheduled Pod Successfully assigned dev/sso-dev-xtremecloud-sso-gcp-2 to gke-xtremecloud-cluster--default-pool-d03f8f59-sht0
20m Warning NetworkNotReady Pod network is not ready: [runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: Kubenet does not have netConfig. This is most likely due to lack of PodCIDR]
20m Normal Pulling Pod pulling image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
19m Normal Pulled Pod Successfully pulled image "quay.io/eupraxialabs/xtremecloud-sso:3.0.2-gcp"
19m Normal Created Pod Created container
19m Normal Started Pod Started container
17m Warning Unhealthy Pod Readiness probe failed: Get http://10.52.3.2:8080/auth/realms/master: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
2m27s Normal Killing Pod Killing container with id docker://xtremecloud-sso-gcp:Need to kill Pod
25m Normal SuccessfulCreate StatefulSet create Pod sso-dev-xtremecloud-sso-gcp-1 in StatefulSet sso-dev-xtremecloud-sso-gcp successful
25m Normal SuccessfulRescale HorizontalPodAutoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target
21m Normal SuccessfulRescale HorizontalPodAutoscaler New size: 3; reason: cpu resource utilization (percentage of request) above target
21m Normal SuccessfulCreate StatefulSet create Pod sso-dev-xtremecloud-sso-gcp-2 in StatefulSet sso-dev-xtremecloud-sso-gcp successful
2m28s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 2; reason: All metrics below target
2m28s Normal SuccessfulDelete StatefulSet delete Pod sso-dev-xtremecloud-sso-gcp-2 in StatefulSet sso-dev-xtremecloud-sso-gcp successful
19m Normal UpdatedLoadBalancer Service Updated load balancer with new hosts
More information is available here on autoscale.
Recovering from a Multi-Cloud Partitioned Network
A partitioned network will certainly affect the replication traffic for the web cache, the LDAP transactions, and the database transactions for the XtremeCloud SSO application.
The keys to properly managing any of our multi-cloud applications is proper monitoring, alerting, and the recovery procedures. That is, what steps are necessary to recover from the partitioned network? An important step in analyzing which CSP has the most correct data, based on transactions that might have committed as the split-brain scenario was occurring.
It is unlikely that end users will ever be aware of a split-brain situation, however, a recovery from a split-brain situation must be handled by DevOps staff. We detail this recovery process in the XtremeCloud SSO Quick Start Guide.
Advanced Deployments
Let’s take a look at how you might start off with a single-cloud deployment, but then migrate to a multi-cloud configuration. In this case, initially, a streamlined DR/COOP is the case since the secondary CSP deployment is in a passive (hot standby) mode. The database is set up for uni-directional replication (UDR), so that all persistent data is available in the standby site. With our provided CI/CD pipeline, you can readily transition from a single-cloud to a multi-cloud (active-active) deployment without any code changes or service disruption.
